3.7 ローカル無料 AI:LM Studio
LM Studio は GGUF モデルを GUI で検索・ダウンロード・読み込みし、Local Server で OpenAI 互換 API を公開するデスクトップアプリです。MiniTavern を使えば、スマホから PC 上のモデルとチャットでき、クラウド API Key は不要です。
コア設定
LM Studio を設定する際に必要な情報:
- ホスト IP:通常
192.168で始まる(例:192.168.1.75) - Base URL 形式:
http://192.168.1.75:1234/v1
重要
- プロトコルは
http(https ではない) - ポートは
1234(LM Studio Local Server の既定。アプリ表示を優先) - URL は OpenAI 互換形式で、末尾に
/v1が必要
例:http://192.168.1.75:1234/v1(192.168.1.75 は LM Studio 画面に表示される LAN IP)
LM Studio を選ぶ理由
- GUI:モデルの検索・ダウンロード・読み込みが簡単
- ローカル無料:クラウド API Key 不要
- プライバシー:会話は LAN 経由で PC 上のモデルが処理
- OpenAI 互換:MiniTavern の その他 LLM に対応
- モデルが豊富:GGUF コミュニティの選択肢が多い
要件
- PC 1 台(本チュートリアルは macOS 例。Windows/Linux も可)
- スマホと PC が同じ Wi-Fi
- 利用中は PC を起動したまま、LM Studio Local Server を実行
- 十分な RAM/VRAM(ロールプレイには 7B 以上推奨)
手順(macOS 例)
準備:LM Studio のインストールとモデルダウンロード
- https://lmstudio.ai/ から LM Studio をインストールし、起動する。
- Discover(モデルライブラリ)で、テスト用の中程度サイズの instruct モデル(例:Qwen2.5-7B-Instruct GGUF。名称はカタログによる)をダウンロードし、完了を待つ。
初回のモデルダウンロードはディスク容量を多く使います。
ステップ 1:Local Server を起動し LAN アクセスを許可
次の 2 つのチェックポイントを完了してから進んでください:
- チェックポイント 1:LM Studio のローカルサーバーのスイッチをオンにする。起動後、Status: Running と表示されること。
- チェックポイント 2:Server Settings で Serve on Local Network を有効にする。同じ Wi-Fi のスマホなどから PC 上の LM Studio にアクセスできるようになります。
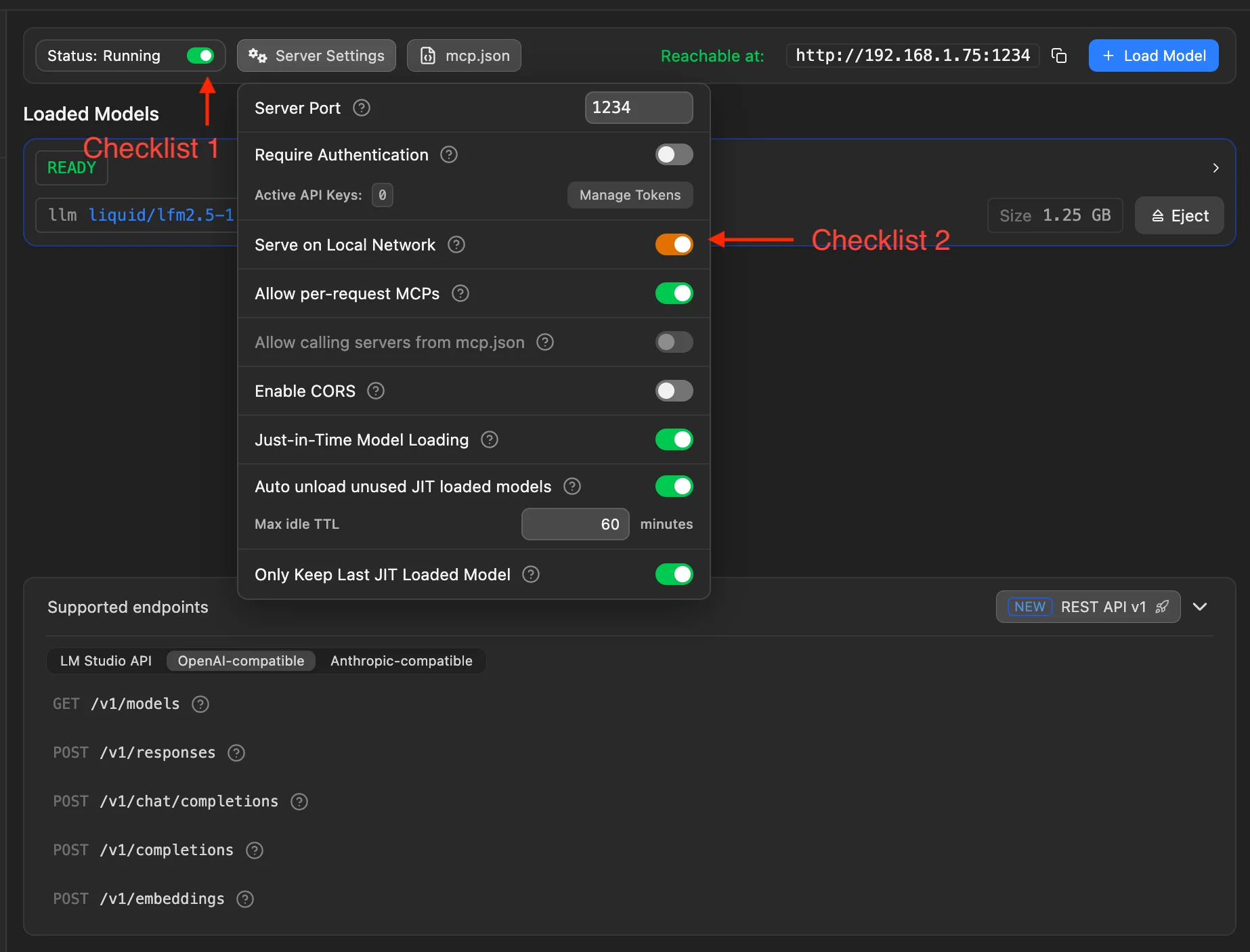
LAN アクセスが必要な理由
- MiniTavern はスマホで動作し、PC 上の LM Studio に LAN 経由で接続する
- 既定では
127.0.0.1のみ許可される場合がある - 有効化後、同じ Wi-Fi の端末は
http://PCのIP:1234/v1を使える
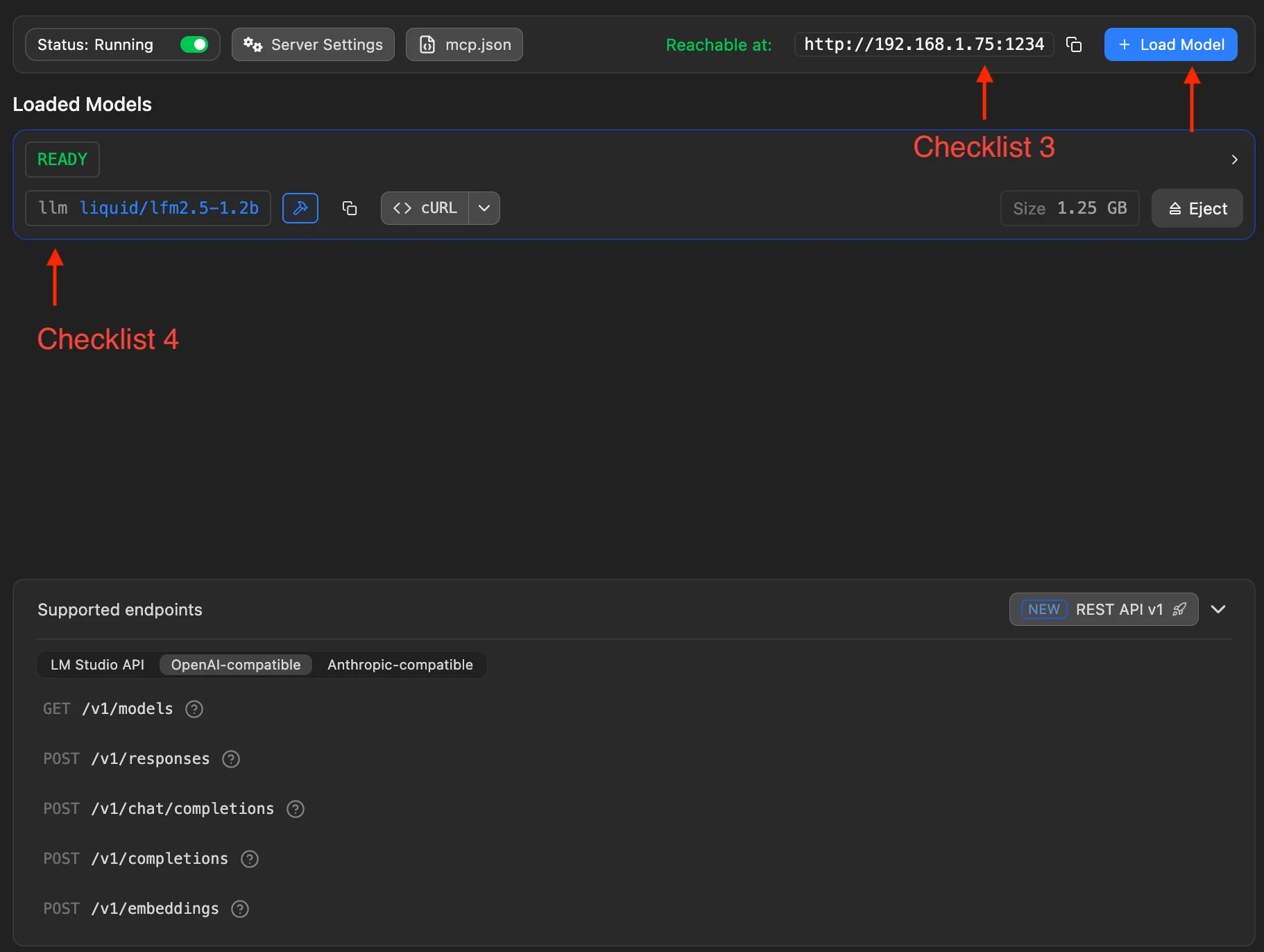
ステップ 2:LAN アドレスの確認とモデル読み込み
次の 2 つのチェックポイントを完了:
- チェックポイント 3:LM Studio に表示される LAN アドレスを確認(例:図の
http://192.168.1.75:1234)。MiniTavern の Base URL の先頭部分(末尾に/v1を付ける)。 - チェックポイント 4:右上の Load Model からダウンロード済みモデルを選択して読み込む。成功すると下に実行中モデルの情報が表示される。
ターミナルでの任意の自己テスト:
bash
curl http://127.0.0.1:1234/v1/modelsモデル id を含む JSON が返れば Local Server は準備完了です。
ステップ 3:MiniTavern で設定
- MiniTavern → 設定 → LLM 設定 → Configure LLM(または AI プロバイダ)。
- API Provider で Other LLM(その他)を選択。
- Base URL にチェックポイント 3 のアドレスを入力し、末尾に
/v1を付ける。
例:チェックポイント 3 が http://192.168.1.75:1234 の場合、Base URL は:
http://192.168.1.75:1234/v1
- Model をタップし、LM Studio で読み込み中のモデルを選んで接続テスト。
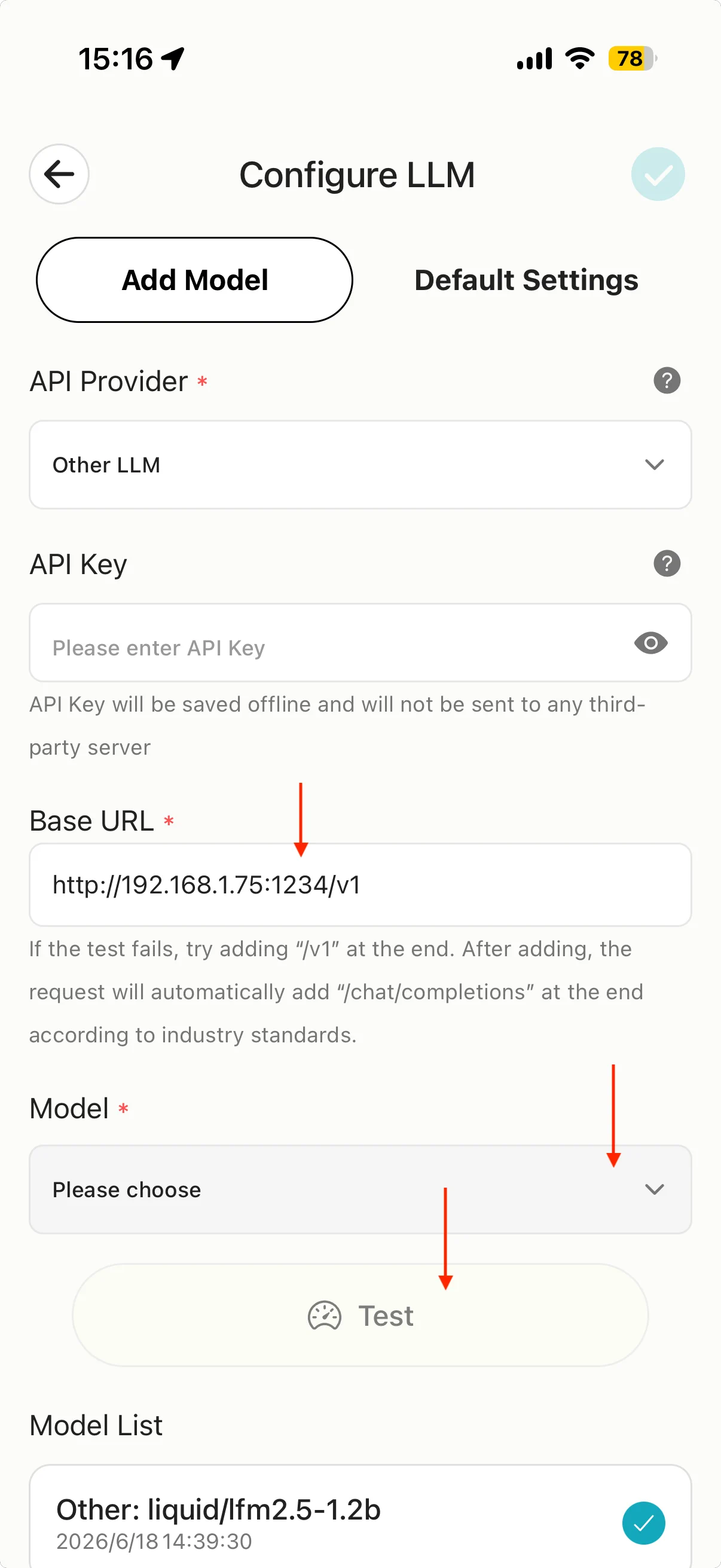
重要
httpのみ(https 不可)- ポートは
1234(アプリ表示を優先) - 末尾は
/v1(OpenAI 互換パス)
API Key:lm-studio など任意のプレースホルダー(ローカルでは通常検証されない)。
接続できない場合:
- モデルが読み込まれ、Local Server が実行中(Status: Running)か確認
- Serve on Local Network が有効か確認
- Base URL が LM Studio の LAN アドレスと一致し、末尾に
/v1があるか確認 - スマホと PC が同じ Wi-Fi か確認
- ファイアウォールがポート
1234をブロックしていないか確認
テスト成功後に保存し、キャラクターカードでチャットできます。
よくある質問
Q: なぜ /v1 サフィックスを使うのですか?
A: これは OpenAI 互換のリクエスト形式です。LM Studio には独自 API もありますが、業界では OpenAI 形式が広く使われます。MiniTavern の Other LLM もこの形式で接続します。LM Studio の /api/v1 で問題がある場合は、本チュートリアルの http://IP:1234/v1 方式に切り替えてください。
Q: モデル一覧が空ですか?
A:
- モデルが Load され、Local Server が起動しているか確認;
- PC のブラウザで
http://127.0.0.1:1234/v1/modelsにアクセスして応答を確認; - MiniTavern の URL に
/v1が含まれるか確認。
Q: 返答品質が低いですか?
A:
- より大きなモデルや高い量子化(7B 以上)を試す;
- LM Studio でコンテキスト長を調整;
- 別のキャラクターカードやプリセットを試す。