3.7 IA gratuite locale : LM Studio
LM Studio permet de rechercher, télécharger et exécuter des modèles GGUF via une interface graphique, puis d’exposer une API compatible OpenAI via Local Server. Avec MiniTavern sur téléphone, vous discutez avec des modèles sur votre PC—sans clé API cloud.
Configuration principale
Pour configurer LM Studio, préparez :
- IP hôte : commence généralement par
192.168(ex.192.168.1.75) - Format Base URL :
http://192.168.1.75:1234/v1
Important
- Utilisez
http(pas https) - Port
1234(défaut Local Server LM Studio ; suivez l’application) - URL compatible OpenAI, avec
/v1à la fin
Exemple : http://192.168.1.75:1234/v1 (192.168.1.75 est l’IP LAN affichée dans LM Studio)
Pourquoi LM Studio ?
- Interface graphique : recherche, téléchargement et chargement de modèles
- Gratuit en local : pas de clé API cloud obligatoire
- Confidentialité : les échanges passent par le LAN vers votre PC
- Compatible OpenAI : fonctionne avec Autre LLM dans MiniTavern
- Large choix de modèles : catalogue GGUF riche
Prérequis
- Un PC (exemple macOS ; Windows/Linux aussi)
- Téléphone et PC sur le même Wi-Fi
- PC allumé avec Local Server LM Studio actif
- RAM/VRAM suffisante (7B+ recommandé pour le jeu de rôle)
Étapes (exemple macOS)
Préparation : installer LM Studio et télécharger un modèle
- Téléchargez et installez LM Studio depuis https://lmstudio.ai/, puis ouvrez l’application.
- Dans Discover (bibliothèque de modèles), recherchez et téléchargez un modèle instruct de taille modérée pour test, par ex. Qwen2.5-7B-Instruct GGUF (nom exact dans le catalogue). Attendez la fin du téléchargement.
Le premier téléchargement de modèle occupe beaucoup d’espace disque.
Étape 1 : démarrer Local Server et autoriser l’accès LAN
Complétez ces deux points de contrôle :
- Point de contrôle 1 : activez l’interrupteur du serveur local LM Studio. Une fois démarré, l’interface doit afficher Status: Running.
- Point de contrôle 2 : dans Server Settings, activez Serve on Local Network pour que le téléphone et d’autres appareils du même Wi-Fi accèdent au PC.
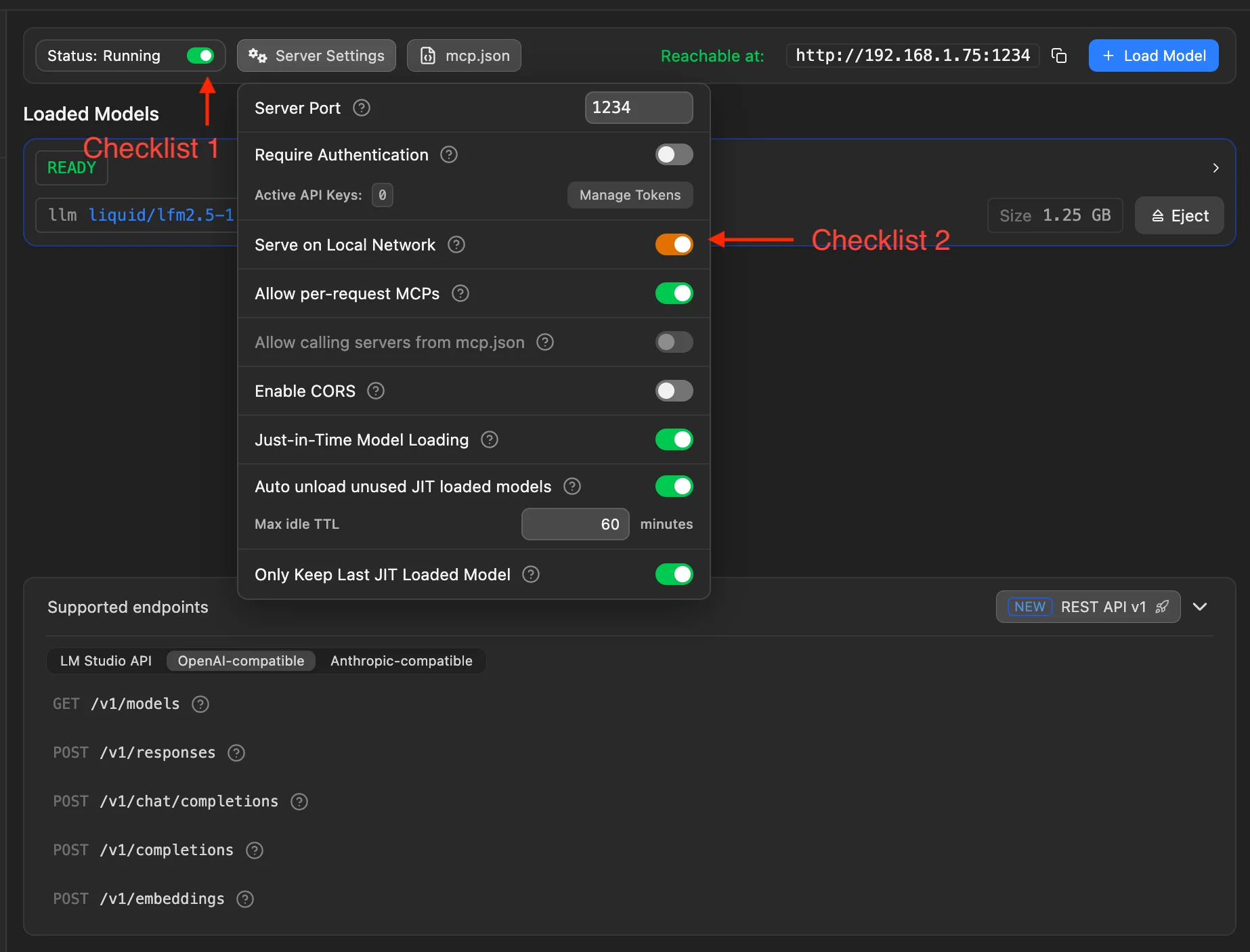
Pourquoi l’accès LAN ?
- MiniTavern tourne sur le téléphone et doit joindre LM Studio sur le PC via le LAN
- Par défaut, seul
127.0.0.1peut être autorisé - Ensuite, le téléphone peut utiliser
http://IP_DU_PC:1234/v1
Étape 2 : confirmer l’adresse LAN et charger un modèle
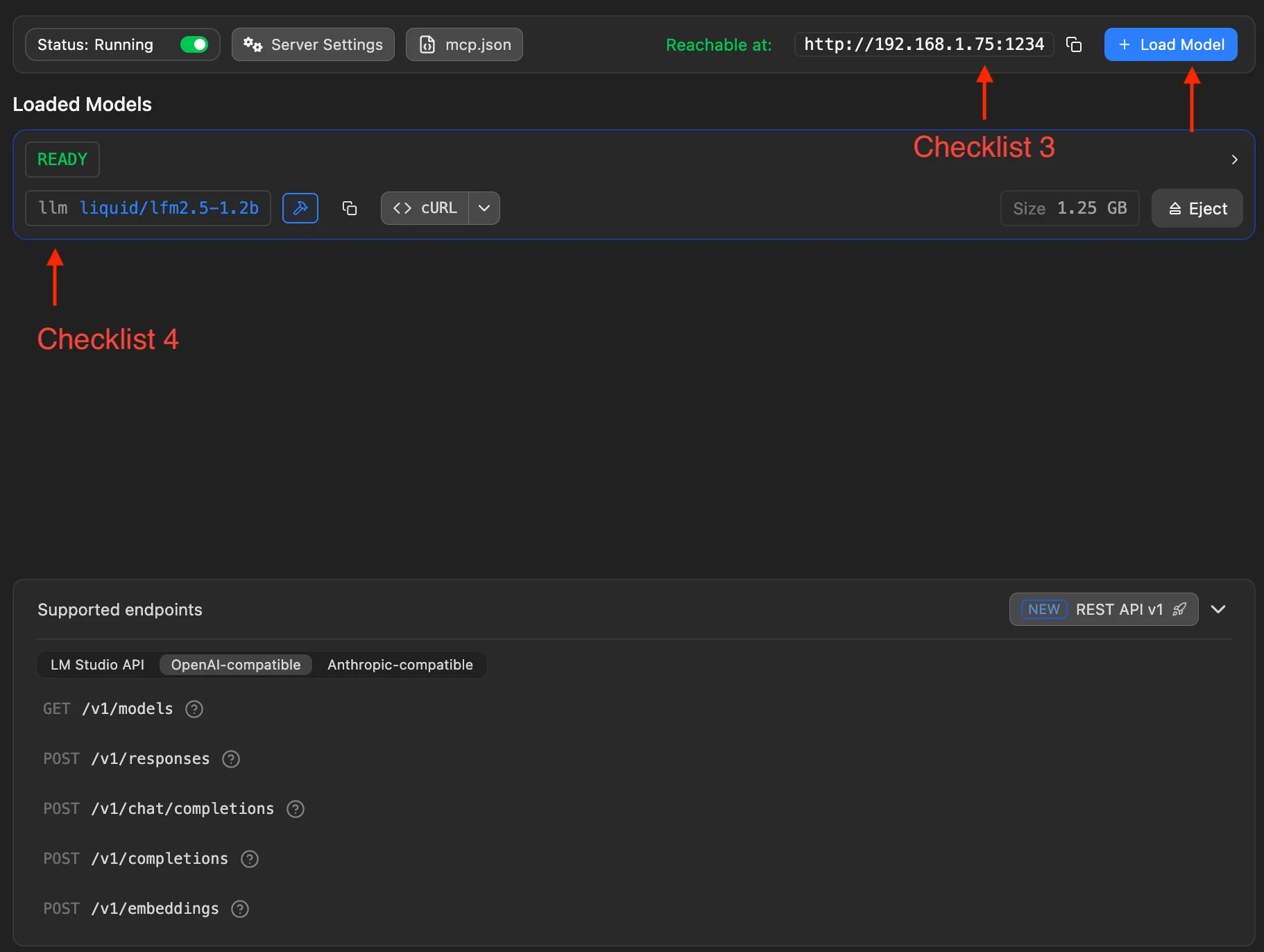
Deux points de contrôle supplémentaires :
- Point de contrôle 3 : vérifiez l’adresse LAN affichée par LM Studio, ex.
http://192.168.1.75:1234sur la capture. C’est le début de la Base URL MiniTavern (ajoutez/v1à la fin). - Point de contrôle 4 : via Load Model (en haut à droite), sélectionnez et chargez un modèle local téléchargé. Les infos du modèle en cours d’exécution apparaissent en dessous.
Test optionnel en terminal :
curl http://127.0.0.1:1234/v1/modelsUn JSON avec des id de modèles confirme que Local Server est prêt.
Étape 3 : configurer MiniTavern
- MiniTavern → Paramètres → Paramètres LLM → Configure LLM (ou Fournisseur IA).
- Sous API Provider, choisissez Other LLM (Autre).
- Dans Base URL, saisissez l’adresse du point de contrôle 3 et ajoutez
/v1.
Exemple : le point de contrôle 3 affiche http://192.168.1.75:1234, alors Base URL :
http://192.168.1.75:1234/v1
- Appuyez sur Model, sélectionnez le modèle chargé dans LM Studio et testez la connexion.
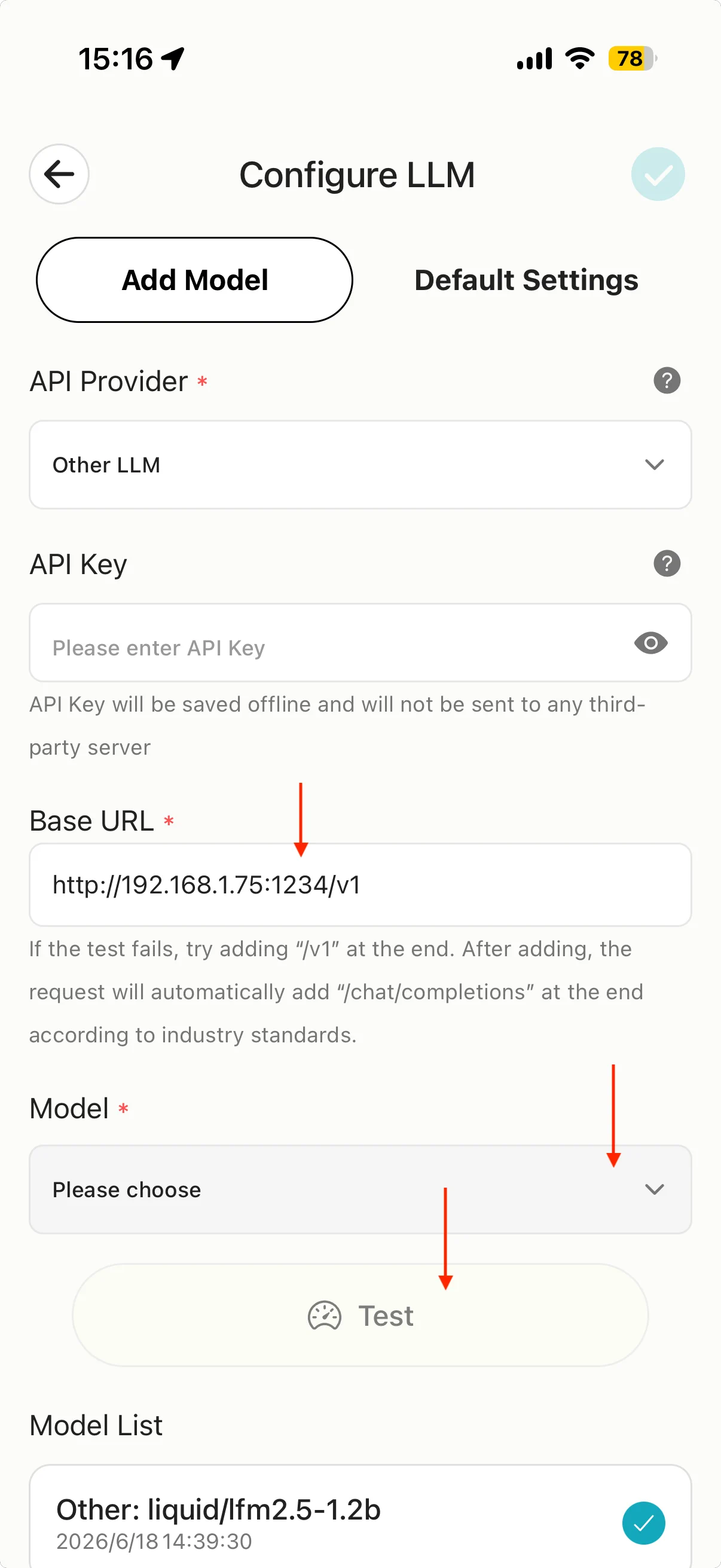
Important
httpuniquement (pas https)- Port
1234(ou valeur affichée dans LM Studio) - Fin obligatoire :
/v1(chemin compatible OpenAI)
Clé API : lm-studio ou toute valeur fictive (souvent non vérifiée en local).
Si la connexion échoue :
- Modèle chargé et Local Server en cours (Status: Running) ?
- Serve on Local Network activé ?
- Base URL identique à l’adresse LAN LM Studio, avec
/v1à la fin ? - Téléphone et PC sur le même Wi-Fi ?
- Pare-feu bloquant le port
1234?
Après un test réussi, enregistrez et discutez avec une fiche personnage.
FAQ
Q : Pourquoi le suffixe /v1 ?
R : C’est le format de requête compatible OpenAI. LM Studio a son propre format API, mais le format OpenAI est plus répandu. Autre LLM dans MiniTavern se connecte ainsi. Si le format /api/v1 de LM Studio pose problème, passez à http://IP:1234/v1 comme dans ce tutoriel.
Q : Liste de modèles vide ?
R :
- Modèle Loadé et Local Server démarré ?
- Sur le PC, ouvrez
http://127.0.0.1:1234/v1/modelsdans le navigateur ; - L’URL MiniTavern contient
/v1?
Q : Qualité de réponse faible ?
R :
- Essayez un modèle plus grand ou une quantification plus élevée (7B+) ;
- Ajustez la longueur de contexte dans LM Studio ;
- Testez d’autres fiches et préréglages.