3.7 Lokale kostenlose KI: LM Studio
LM Studio ist ein Desktop-Tool zum Suchen, Herunterladen und Ausführen von GGUF-Modellen mit GUI. Über Local Server stellt es eine OpenAI-kompatible API bereit. Mit MiniTavern auf dem Handy chatten Sie mit Modellen auf Ihrem PC—ohne Cloud-API-Key.
Kernkonfiguration
Für die LM-Studio-Einrichtung benötigen Sie:
- Host-IP: meist beginnend mit
192.168(z. B.192.168.1.75) - Base-URL-Format:
http://192.168.1.75:1234/v1
Wichtig
- Nur
http(nicht https) - Port
1234(LM Studio Local Server Standard; App-Anzeige beachten) - URL muss OpenAI-kompatibel sein, mit
/v1am Ende
Beispiel: http://192.168.1.75:1234/v1 (192.168.1.75 ist die in LM Studio angezeigte LAN-IP)
Warum LM Studio?
- GUI: Modelle suchen, laden und starten ohne viel Kommandozeile
- Lokal kostenlos: keine Cloud-API-Key-Pflicht
- Datenschutz: Gespräche laufen per LAN zum PC
- OpenAI-kompatibel: funktioniert mit MiniTavern Other LLM
- Große Modellauswahl: reichhaltiger GGUF-Katalog
Voraussetzungen
- Ein PC (macOS-Beispiel; Windows/Linux ebenfalls möglich)
- Handy und PC im gleichen Wi-Fi
- PC bleibt an, LM Studio Local Server läuft
- Genug RAM/VRAM (für Rollenspiel 7B+ empfohlen)
Schritte (macOS-Beispiel)
Vorbereitung: LM Studio installieren und Modell laden
- LM Studio von https://lmstudio.ai/ installieren und starten.
- In Discover (Modellbibliothek) ein mittelgroßes Instruct-Modell zum Testen suchen und herunterladen, z. B. Qwen2.5-7B-Instruct GGUF (genauer Name im Katalog). Download abwarten.
Der erste Modell-Download benötigt viel Speicherplatz.
Schritt 1: Local Server starten und LAN-Zugriff erlauben
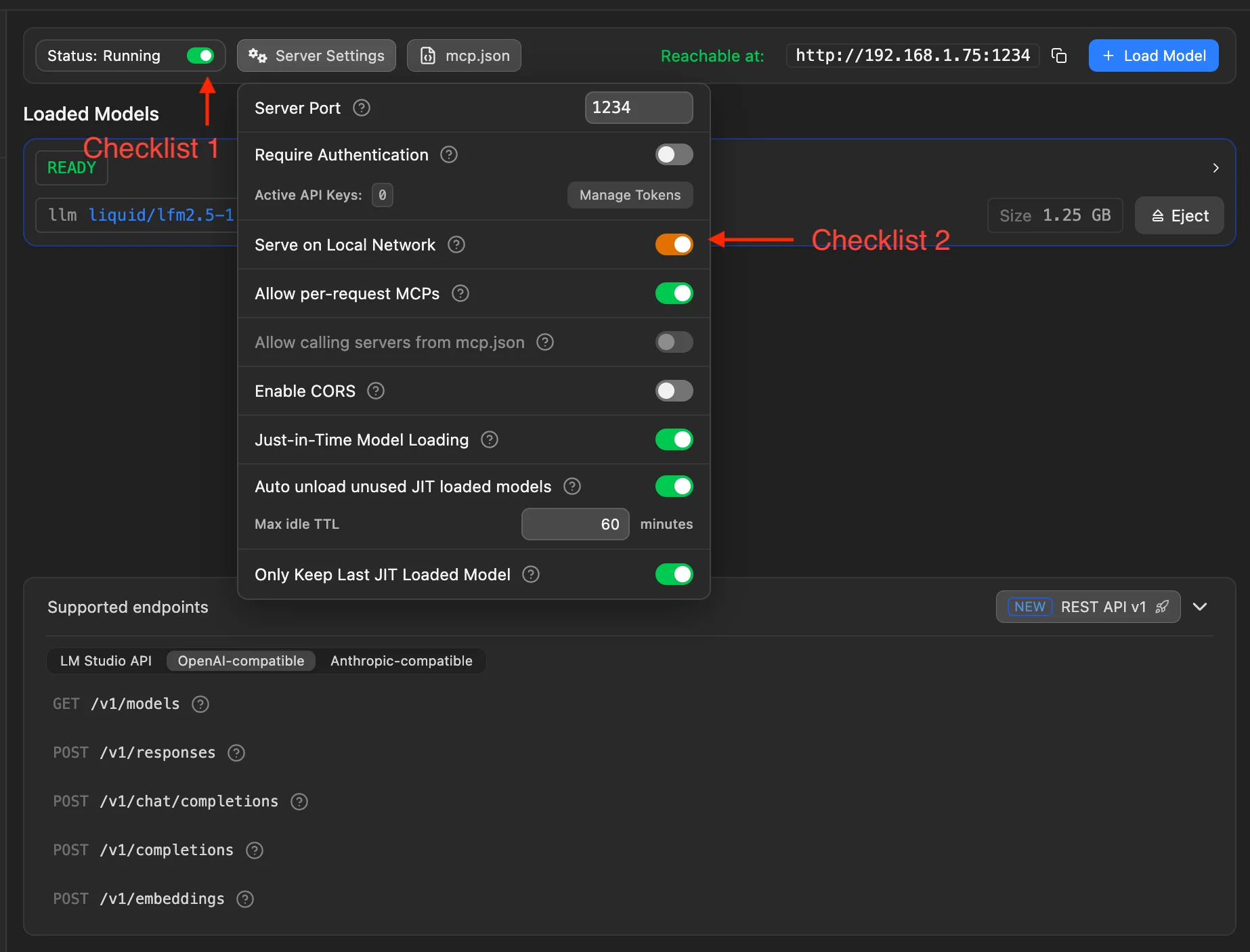
Erledigen Sie diese zwei Prüfpunkte:
- Prüfpunkt 1: Schalter für den LM-Studio-Lokalserver einschalten. Bei laufendem Server sollte Status: Running erscheinen.
- Prüfpunkt 2: In Server Settings Serve on Local Network aktivieren, damit Handy und andere Geräte im gleichen Wi-Fi den PC erreichen.
Warum LAN-Zugriff?
- MiniTavern läuft auf dem Handy und muss LM Studio am PC über das LAN erreichen
- Standardmäßig ist oft nur
127.0.0.1erlaubt - Danach kann das Handy
http://PC-IP:1234/v1nutzen
Schritt 2: LAN-Adresse prüfen und Modell laden
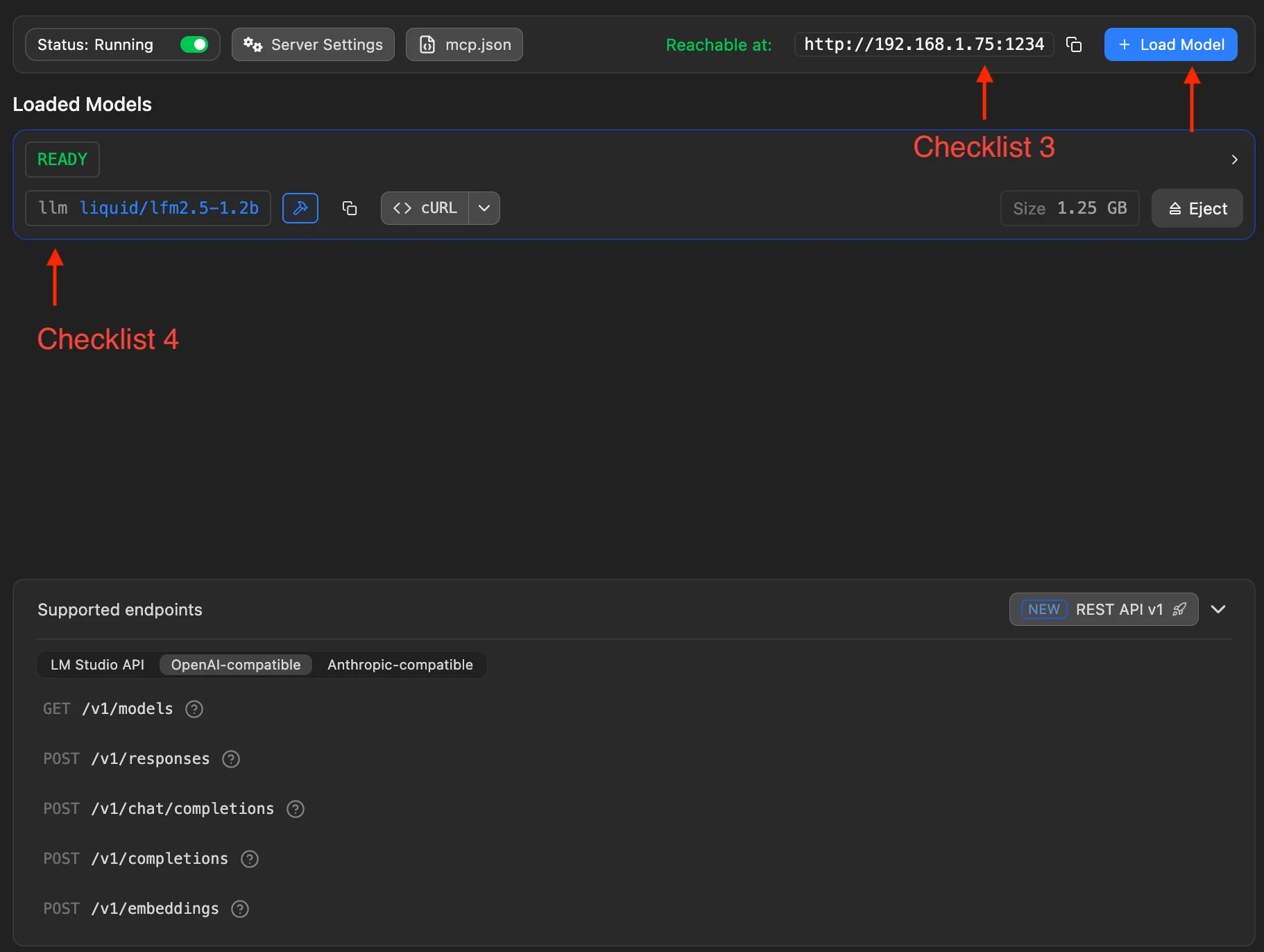
Weitere zwei Prüfpunkte:
- Prüfpunkt 3: LAN-Adresse in LM Studio prüfen, z. B.
http://192.168.1.75:1234im Screenshot. Das ist der Anfang der MiniTavern-Base URL (am Ende/v1anhängen). - Prüfpunkt 4: Über Load Model (oben rechts) ein heruntergeladenes Modell laden. Darunter erscheinen Infos zum laufenden Modell.
Optionaler Test im Terminal:
curl http://127.0.0.1:1234/v1/modelsJSON mit Modell-IDs bedeutet: Local Server ist bereit.
Schritt 3: MiniTavern konfigurieren
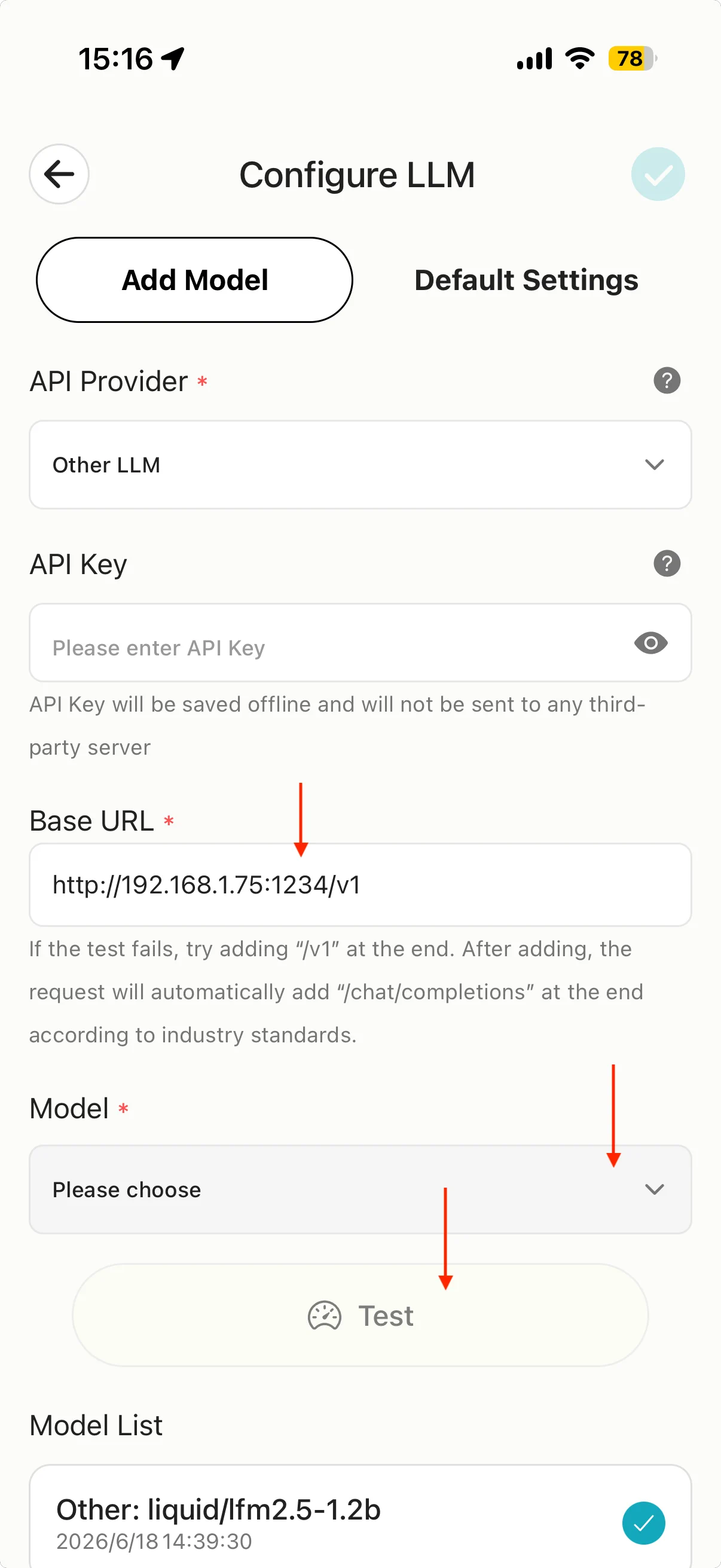
- MiniTavern → Einstellungen → LLM-Einstellungen → Configure LLM (oder KI-Anbieter).
- Unter API Provider Other LLM wählen.
- In Base URL die Adresse aus Prüfpunkt 3 eintragen und
/v1anhängen.
Beispiel: Prüfpunkt 3 zeigt http://192.168.1.75:1234, dann Base URL:
http://192.168.1.75:1234/v1
- Model tippen, geladenes LM-Studio-Modell wählen und Verbindung testen.
Wichtig
- Nur
http(nicht https) - Port
1234(oder App-Anzeige) - Ende muss
/v1sein (OpenAI-kompatibler Pfad)
API Key: lm-studio oder beliebiger Platzhalter (lokal meist ohne Prüfung).
Bei Verbindungsfehlern:
- Modell geladen und Local Server läuft (Status: Running)?
- Serve on Local Network aktiv?
- Base URL entspricht LM-Studio-LAN-Adresse und endet mit
/v1? - Handy und PC im gleichen Wi-Fi?
- Firewall blockiert Port
1234?
Nach erfolgreichem Test speichern und mit Charakterkarte chatten.
FAQ
F: Warum das Suffix /v1?
A: Das ist das OpenAI-kompatible Anfrageformat. LM Studio hat ein eigenes API-Format, aber OpenAI-Format wird häufiger genutzt. MiniTavern Other LLM verbindet sich so. Bei Problemen mit LM Studios /api/v1 wechseln Sie zu http://IP:1234/v1 wie in dieser Anleitung.
F: Leere Modellliste?
A:
- Modell Loaded und Local Server läuft?
- Im Browser am PC:
http://127.0.0.1:1234/v1/modelsprüfen; - MiniTavern-URL enthält
/v1?
F: Schlechte Antwortqualität?
A:
- Größeres Modell oder höhere Quantisierung (7B+) testen;
- Kontextlänge in LM Studio anpassen;
- Andere Charakterkarten und Presets testen.