3.7 IA local gratuita: LM Studio
LM Studio es una herramienta de escritorio para buscar, descargar y ejecutar modelos GGUF con interfaz gráfica, y exponer una API compatible con OpenAI mediante Local Server. Con MiniTavern en el móvil puedes chatear con modelos en tu PC sin clave API en la nube.
Configuración principal
Al configurar LM Studio, prepara lo siguiente:
- IP del host: suele empezar por
192.168(p. ej.192.168.1.75) - Formato Base URL:
http://192.168.1.75:1234/v1
Importante
- Usa
http(no https) - Puerto
1234(predeterminado de Local Server; sigue lo que muestre la app) - URL compatible con OpenAI, con
/v1al final
Ejemplo: http://192.168.1.75:1234/v1 (192.168.1.75 es la IP LAN mostrada en LM Studio)
¿Por qué LM Studio?
- Interfaz gráfica: buscar, descargar y cargar modelos sin mucha terminal
- Gratis en local: inferencia local sin clave API obligatoria
- Privacidad: las conversaciones van por LAN al PC
- Compatible con OpenAI: funciona con Otro LLM en MiniTavern
- Amplio catálogo GGUF
Requisitos
- Un PC (ejemplo macOS; Windows/Linux también)
- Móvil y PC en la misma Wi-Fi
- PC encendido con Local Server de LM Studio en ejecución
- RAM/VRAM suficiente (7B+ recomendado para roleplay)
Pasos (ejemplo macOS)
Preparación: instalar LM Studio y descargar un modelo
- Descarga e instala LM Studio desde https://lmstudio.ai/ y ábrelo.
- En Discover (biblioteca de modelos), busca y descarga un modelo instruct de tamaño moderado para pruebas, p. ej. Qwen2.5-7B-Instruct GGUF (nombre exacto en el catálogo). Espera a que termine la descarga.
La primera descarga de modelo ocupa mucho espacio en disco.
Paso 1: iniciar Local Server y permitir acceso LAN
Completa estos dos puntos de verificación:
- Punto de verificación 1: activa el interruptor del servidor local de LM Studio. Al arrancar, la interfaz debe mostrar Status: Running.
- Punto de verificación 2: en Server Settings, activa Serve on Local Network para que el móvil y otros dispositivos en la misma Wi-Fi accedan al PC.
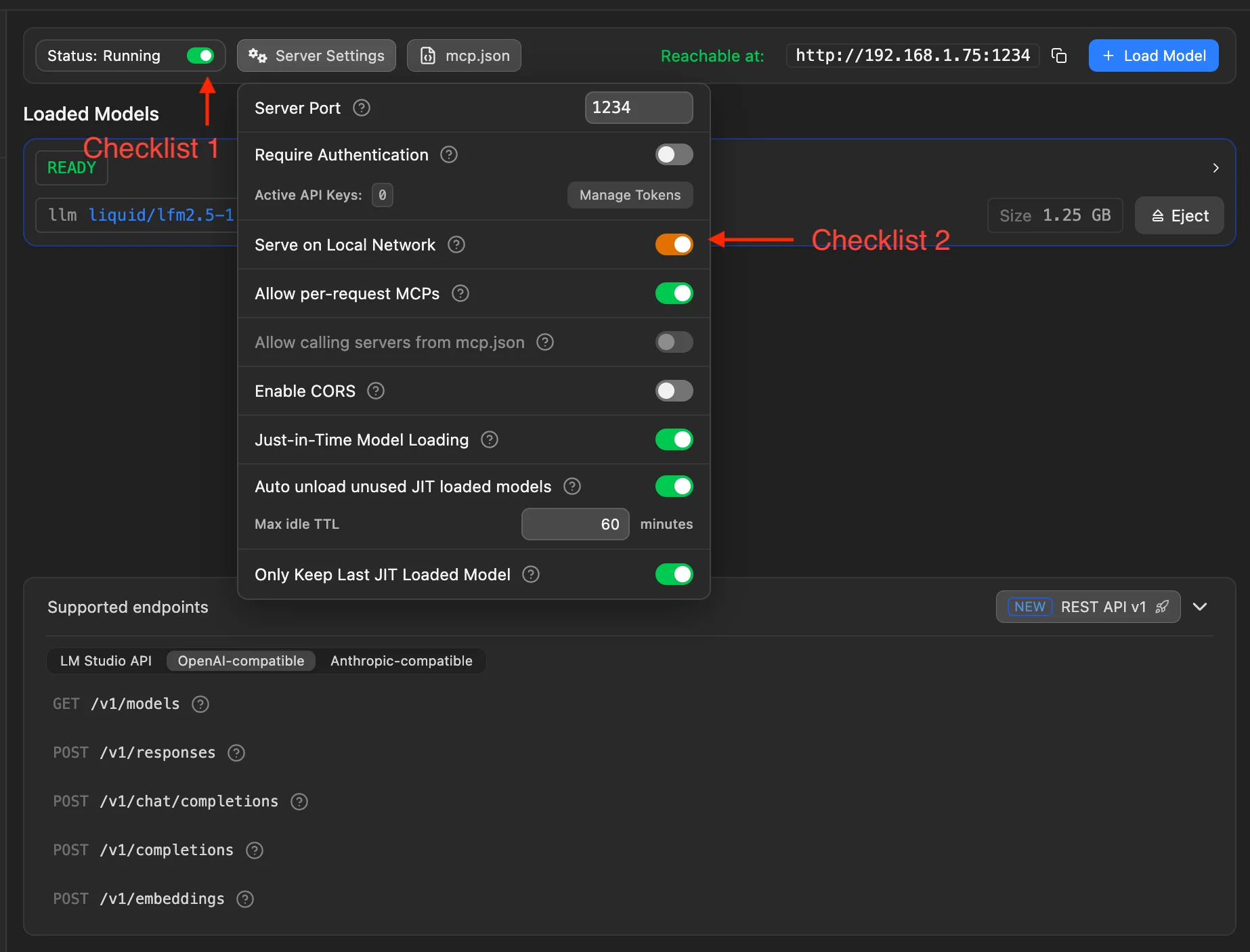
¿Por qué acceso LAN?
- MiniTavern corre en el móvil y debe llegar a LM Studio en el PC por LAN
- Por defecto puede permitirse solo
127.0.0.1 - Tras activarlo, el móvil puede usar
http://IP_DEL_PC:1234/v1
Paso 2: confirmar la dirección LAN y cargar un modelo
Completa estos dos puntos:
- Punto de verificación 3: revisa la dirección LAN que muestra LM Studio, p. ej.
http://192.168.1.75:1234en la captura. Es el inicio de la Base URL en MiniTavern (añade/v1al final). - Punto de verificación 4: con Load Model (arriba a la derecha), selecciona y carga un modelo local descargado. Abajo aparecerá la información del modelo en ejecución.
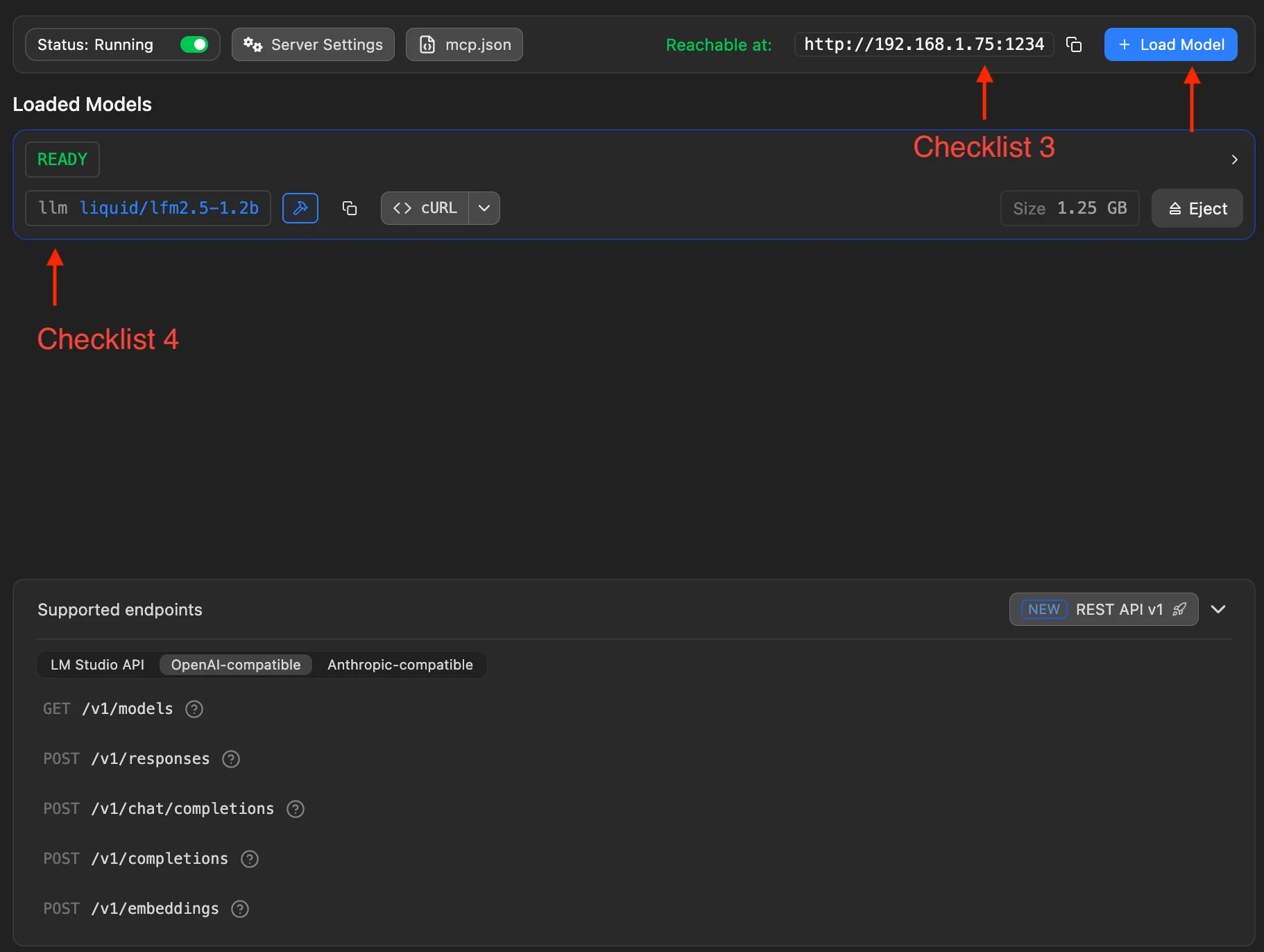
Prueba opcional en terminal:
curl http://127.0.0.1:1234/v1/modelsJSON con ids de modelos significa que Local Server está listo.
Paso 3: configurar MiniTavern
- MiniTavern → Ajustes → Ajustes LLM → Configure LLM (o Proveedor de IA).
- En API Provider, elige Other LLM (Otro).
- En Base URL, escribe la dirección del punto de verificación 3 y añade
/v1.
Ejemplo: si el punto 3 muestra http://192.168.1.75:1234, Base URL:
http://192.168.1.75:1234/v1
- Pulsa Model, elige el modelo cargado en LM Studio y prueba la conexión.
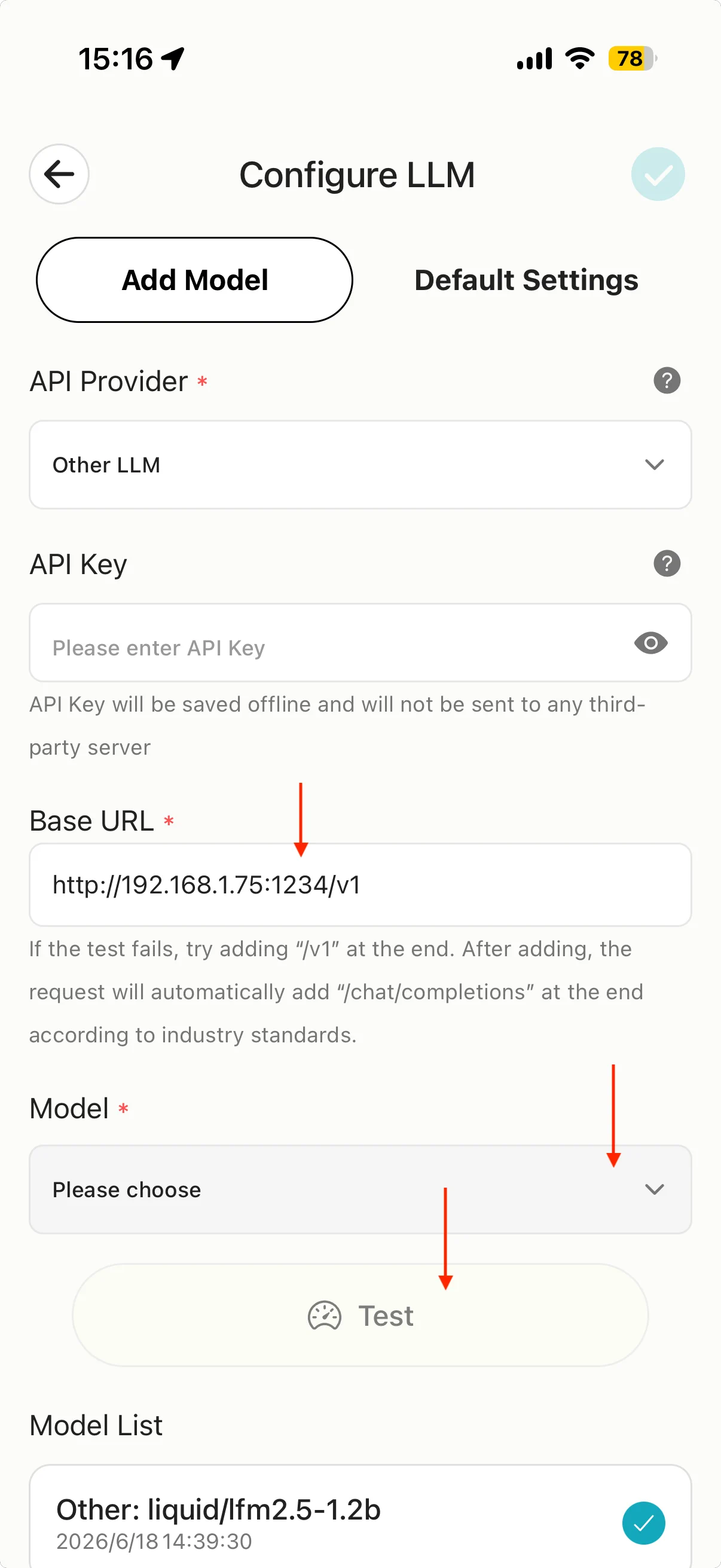
Importante
- Solo
http(no https) - Puerto
1234(o el que muestre LM Studio) - Debe terminar en
/v1(ruta compatible con OpenAI)
API Key: lm-studio u otro valor de relleno (el servidor local suele no validarla).
Si falla la conexión:
- ¿Modelo cargado y Local Server en ejecución (Status: Running)?
- ¿Serve on Local Network activado?
- ¿Base URL coincide con la dirección LAN de LM Studio y termina en
/v1? - ¿Móvil y PC en la misma Wi-Fi?
- ¿Firewall bloqueando el puerto
1234?
Tras una prueba exitosa, guarda y chatea con una tarjeta de personaje.
Preguntas frecuentes
P: ¿Por qué el sufijo /v1?
R: Es el formato de solicitud compatible con OpenAI. LM Studio tiene su propio formato API, pero el formato OpenAI es más habitual. Otro LLM en MiniTavern se conecta así. Si el formato /api/v1 de LM Studio da problemas, usa http://IP:1234/v1 como en este tutorial.
P: ¿Lista de modelos vacía?
R:
- Confirma que el modelo está Loadeado y Local Server activo;
- En el navegador del PC, abre
http://127.0.0.1:1234/v1/models; - Confirma que la URL en MiniTavern incluye
/v1.
P: ¿Mala calidad de respuesta?
R:
- Prueba un modelo mayor o mayor cuantización (7B+);
- Ajusta la longitud de contexto en LM Studio;
- Prueba otras tarjetas y presets.